


今日は、検索式とは直接関係なくても、キーワードの設定によって検索結果が表示される場合のヒントをいくつかご紹介したいと思います。
例えば、(MSNのような)ソースからの記事で、無関係な記事のプレビューにキーワードが使われていたり、広告が紛れ込んでいたりします。設定したキーワードが一度だけ使われているものの、内容は関連性のない記事が紛れ込んでいるかもしれません。
ここでは、キーワードがメンションの焦点となるようにするために使用できる2つの簡単な演算子を紹介します:頻度{ }演算子と近接NEAR演算子です。
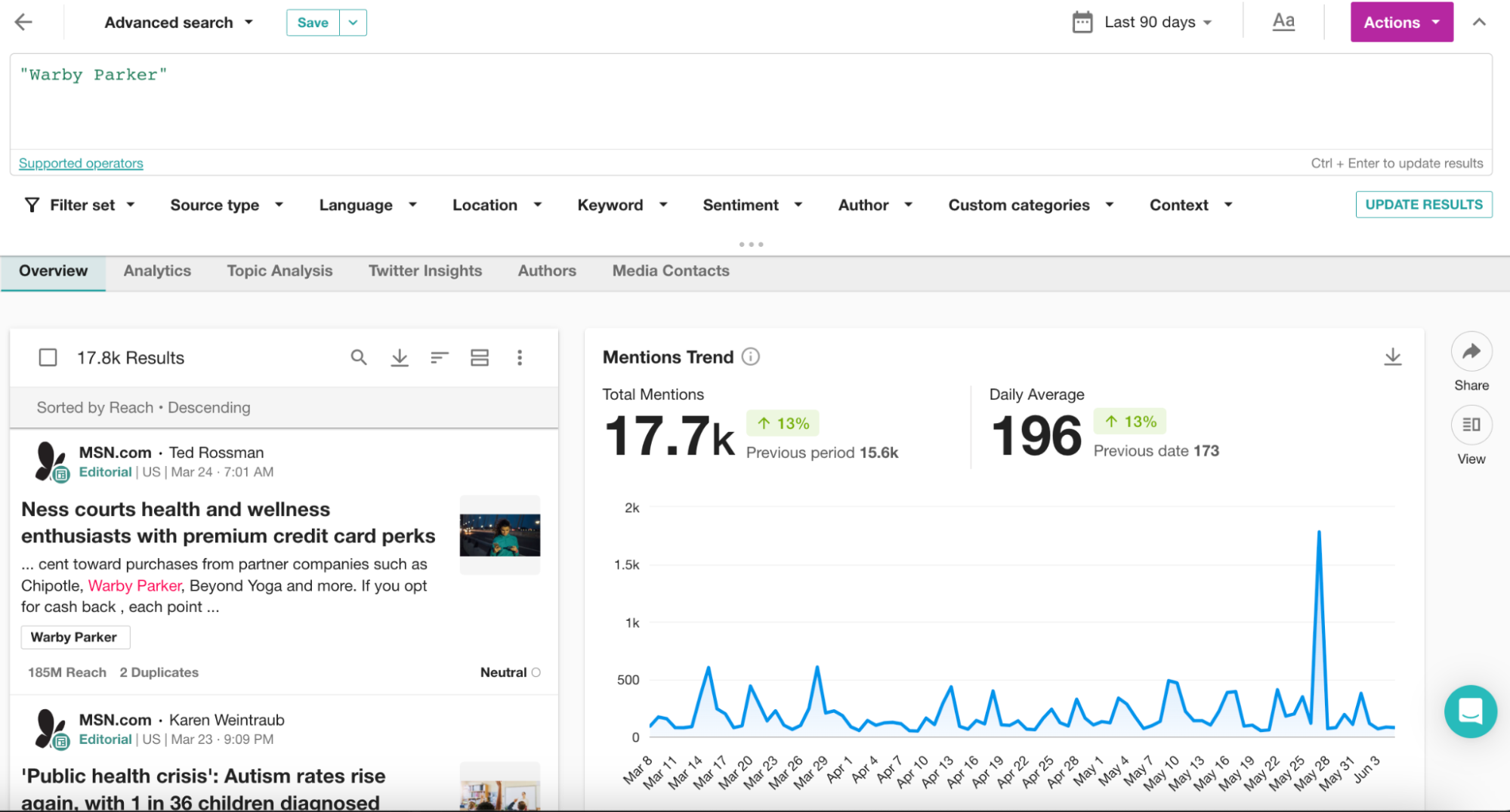
まず、頻度{ }演算子から始めましょう。この演算子を使用することで、キーワードが各メッセージに何回表示されるかを指定することができます。例えば、 “Warby Parker”{2}で検索した場合、「Warby Parker」というフレーズは、全てのメンションの中で少なくとも2回表示されなければなりません。私は通常、MSNのような「関連記事」セクションがあるサイトからのメンションをフィルタリングするには、2という数字を使えば十分だと感じています。しかし、特に広告を排除しようとする場合は、{3}やそれ以上の数字を自由に試してみてください。
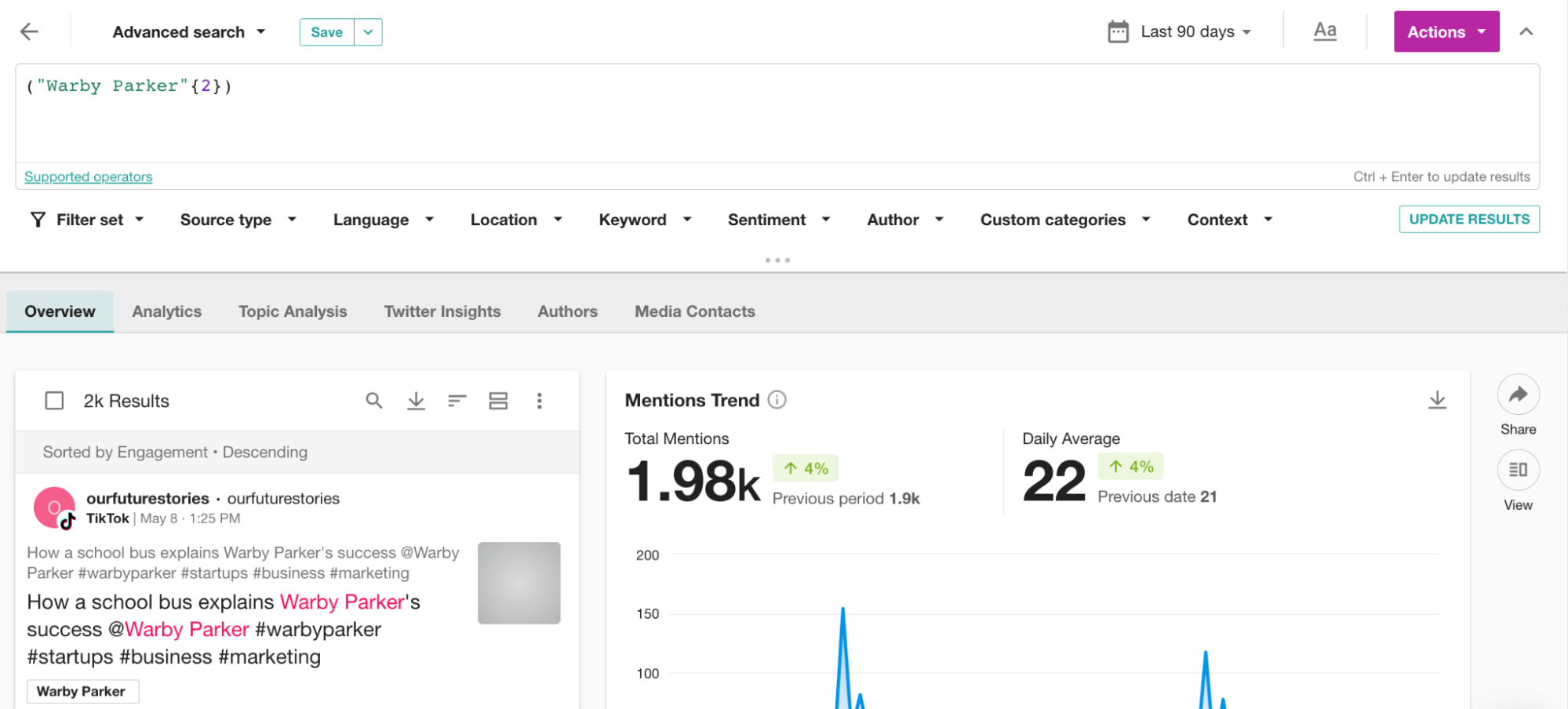
では、さらによく使うNEAR演算子について説明しましょう。 “Warby Parker” NEAR/10 qualityクエリを使用すると、「Warby Parker」と「quality」が10ワード以内に出現するメンションを見つけることができます。「NEAR/」の後の数字を変更することで、近接度を調整することができます。例えば、 “Warby Parker” NEAR/5 qualityは、「Warby Parker」と「quality」が5ワード以内にあるメンションに結果を絞り込みます。以下のスクリーンショットでは、AND演算子を使用した場合との結果の違いにお気づきでしょう。
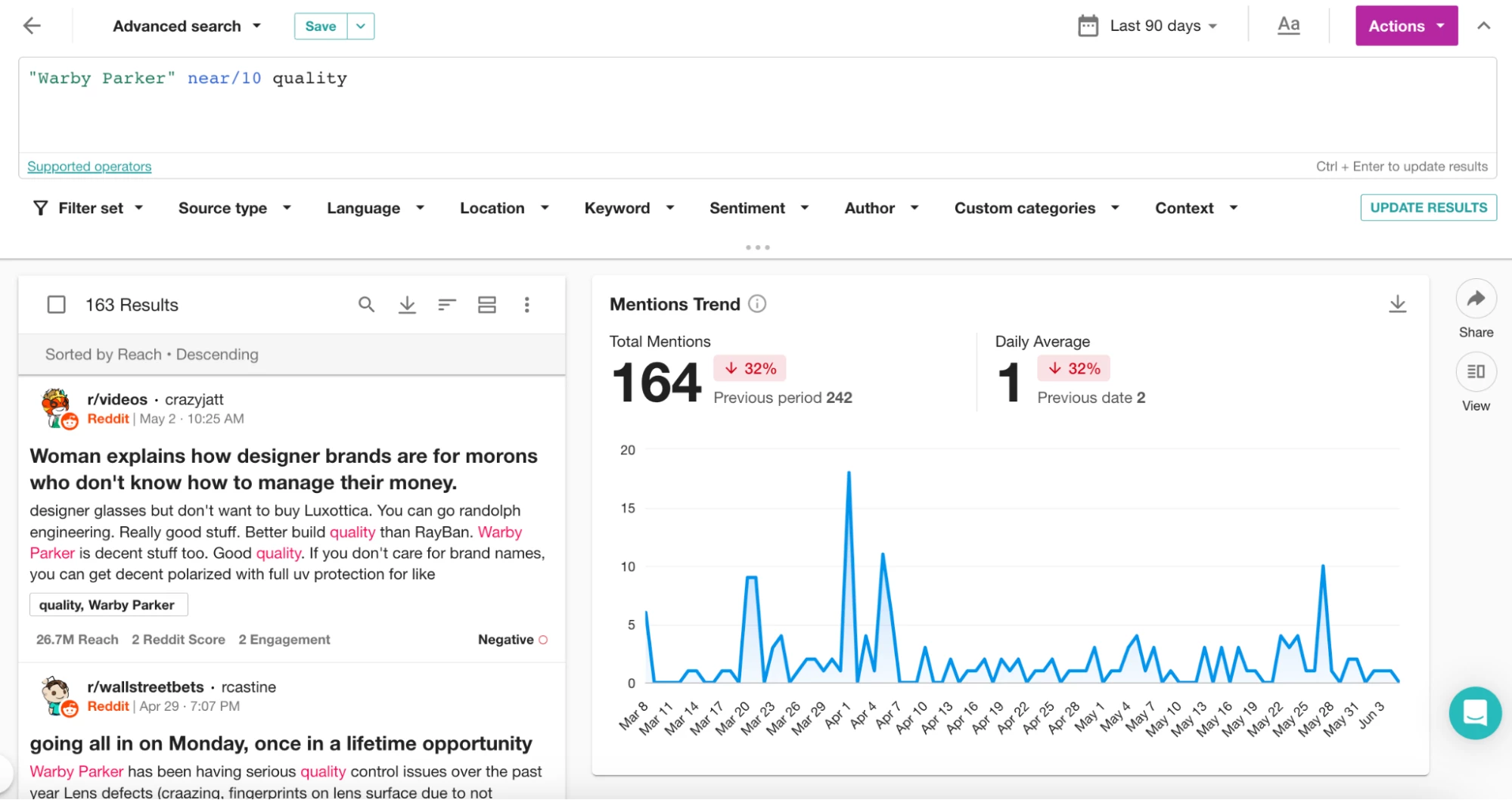
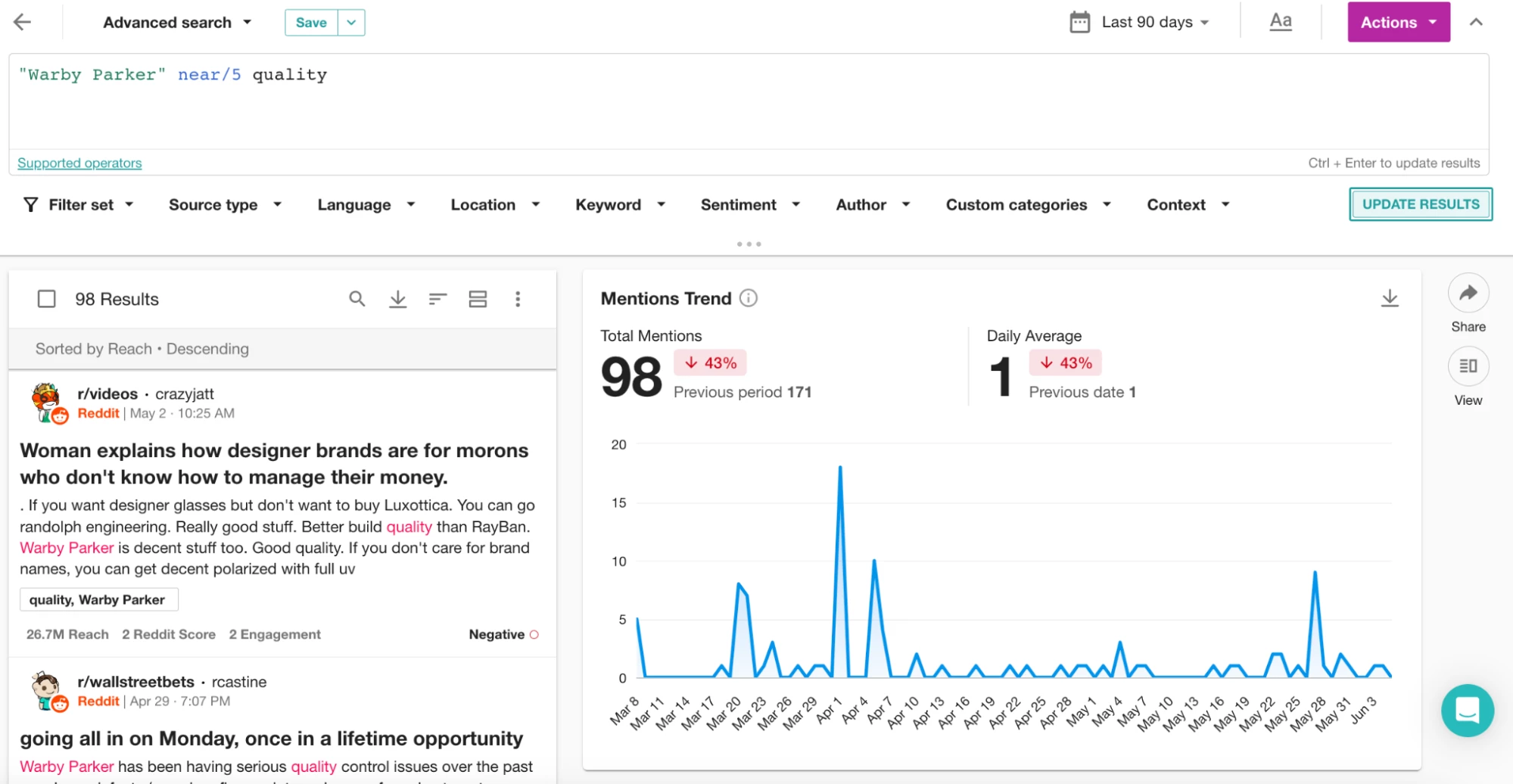
近接演算子を試すときは、NEAR/5、NEAR/8、NEAR/12 など、さまざまな値を試してみてください。さらに、単語のグループで「NEAR」演算子を使用できることを覚えておいてください。例えば、より広範な「品質」キーワードのリストに関連するWarby Parkerのメンションを見つけたい場合は、次のように括弧で囲むだけです:
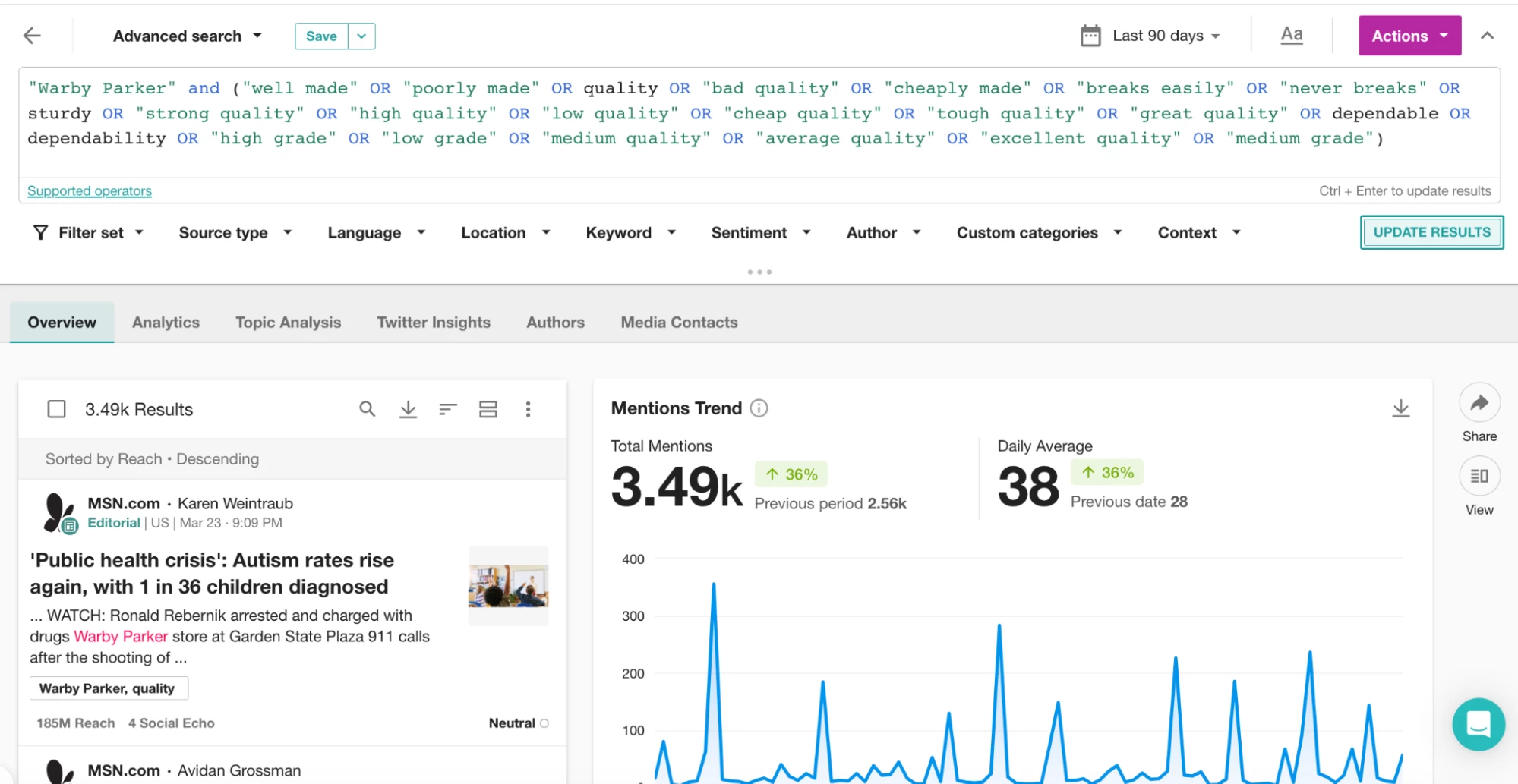
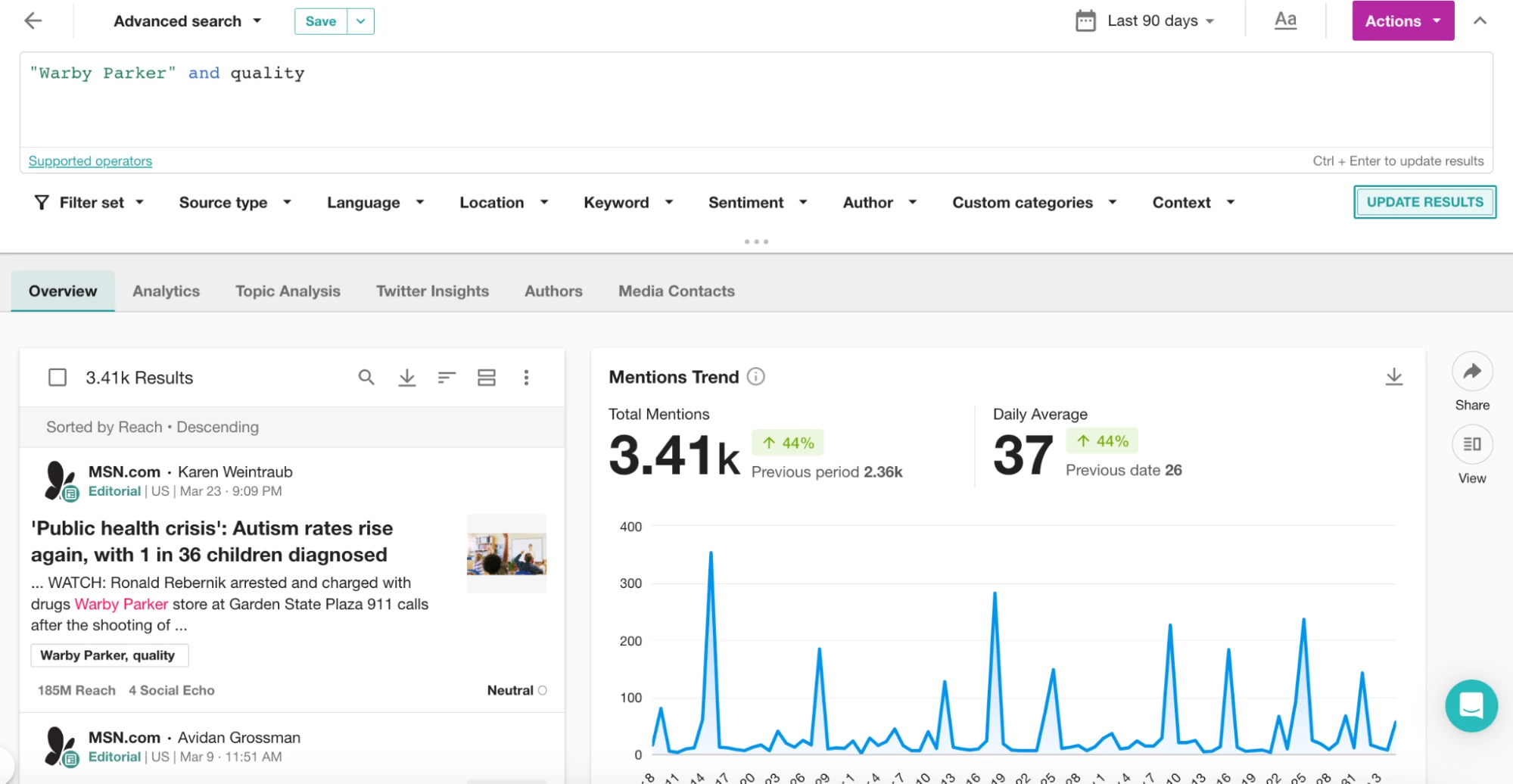
349,000件がANDを使用してメンションしていますが、結果はすべて適切ではありません。NEAR/10で試してみましょう。
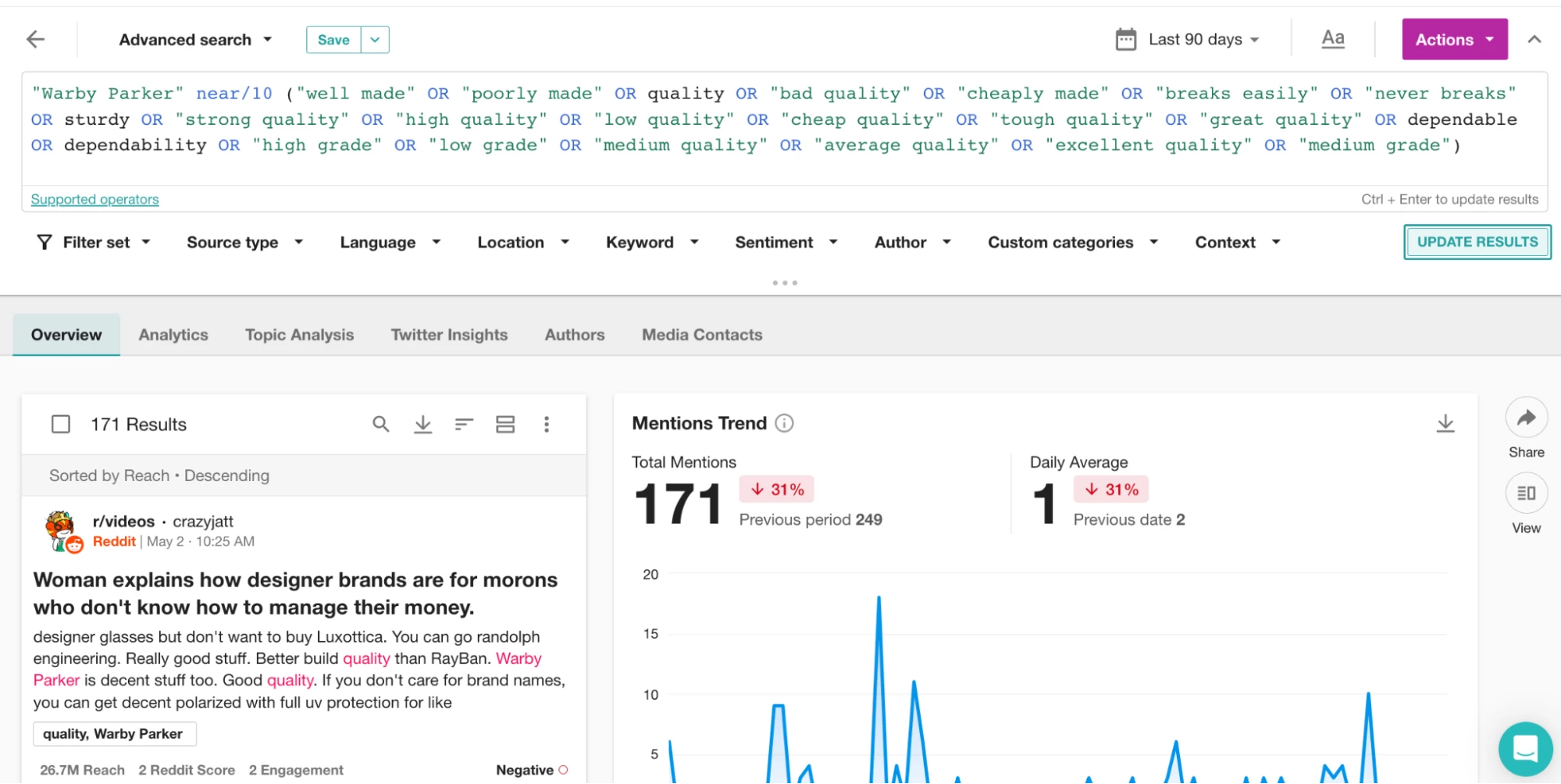
そうすることで、検索結果の関連性が高まります。
これらのヒントが、検索でより関連性の高い言及を達成するのに役立つことを願っています。ご不明な点がございましたら、お気軽にお問い合わせください!これらの演算子に関する追加情報や技術的なヒントについては、ブーリアンライブラリーの「近接演算子」のセクションをぜひご覧ください。
それではまた! 🫡